Since we have already got some bases on how CNN works, so this post I prefer to focus more on the ideologies that make these architectures unique and the general technics that can improve the performance of the CNN. If you are new to this, please visit my previous post, I believe it can help you to understand the paper or at least get the key point of the paper.
ZFNet
Related paper is:Visualizing and Understanding Convolutional Networks, published on Nov. 2013.
Achievement
ZFNet won the first place of ImageNet 2013 classification competition, the top-5 test error rate by combine multiple models (6 in total) is 14.8%.
Architecture
The architecture derives from AlexNet. The difference resides in (i) reduced the 1st layer filter size from 11x11 to 7x7 and (ii) made the stride of the convolution 2, rather than 4. Many later research and experiments show that by reducing the conv. stride and the conv. kernel size can avoid representation bottleneck, so the performance can be improved.
Convnet Visualization
This paper is famous for its visualization scheme! They raised a multi-layerd deconvolutional network (deconvnet) to visualize “the input stimuli that excite individual feature maps at any layer in the model” and it also “allows us to observe the evolution of features during training and to diagnose potential problems with the model”.
Unpooling
Unpooling is a impossible operation, they used the way to approximate the feature map before the pooling operation in the forward network, the way is to record the position of each value of the pooled map in the unpooled feature maps, the rest position will be padded zero.
Rectification
After Unpooling, they add a rectification layer to guarantee the value is positive. My intuition is that this layer is invalid at the first reverse step, because the result must be always positive, but after the deconvolution operation, the value could be negative.
Filtering
This filtering cannot be more controversial. The name “deconvnet” is quite misleading. The way they do it to use the trained filter, do the vertical flip and horizontal flip to get a new filter. The new filter will serve as the filter to do the deconvolution. They didn’t explicitly address the padding scheme for the ReLUed feature maps at the inverse process.
The way I understand it is as follows:
Let’s say you have a 3x3 matrix and a 3x3 conv. kernel. If you want to recover the original matrix from conv. result. Maybe you should do the following:

This is the most simple case, may be they just want to do this kind of thing to reveal how the network takes effect on the input image.
I cannot guarantee my understanding is correct here, if you have any other explanation, please let me know!
Network in Network
Related paper is:Network In Network, published on Mar. 2014.
Achievement
Provide 8.81% error rate on cifar-10 dataset. Better than previous state-of-the-art.
Mlpconv layer
The concept of network in network or mlpconv layer inspires the Inception module. They replace the convolutional layer in CNN with a multi-layer perceptron, so the conv. op. can be more representative.
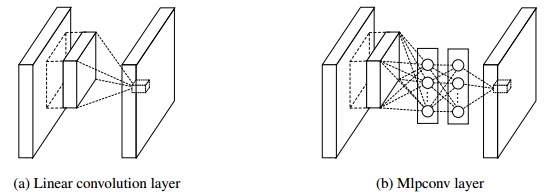
Global Average Pooling
Global average pooling layer is usually the last layer of the network, it was raised to replace the fully connected layer. The idea is to use a feature map as the output of the network, each feature map represents a class, take the average of the value of the feature map to classify the image into different classes.
The author claims that GAP can be seen as a sort of regularizer to reduce the overfitting.
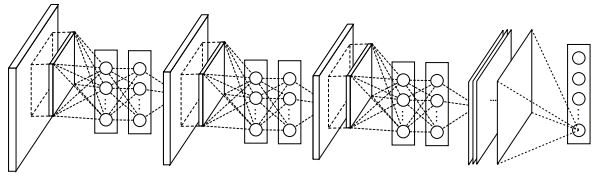
Structure
The whole structure of the network is shown as follows:
VGGNet
Related paper is:Very Deep Convolutional Networks for Large-Scale Image Recognition, published on Sep. 2014.
Achievement
VGGNet get the first place in ImageNet Challenge 2014 in localization and second place in classification tracks. VGGNet is one of the best architectures for deep learning beginners for its simplicity.
The later ResNet uses VGG-like structure as comparison to illustrate the effect of identity mapping operation. The author claims that the best single model prediction on ILSVRC test set top-5 error rate is 7.1%.
Network Architecture
The input of the network is 224x224 RGB image. For each input, subtract global mean from each pixel. Then, the image will pass through a stack of conv. layers. The conv. filter size is 3x3, which is the smallest size to capture the notion of left/right, up/down, center. Under certain scenario, 1x1 filters will be adopted, it can be seen as a linear transformation of the input channels. Conv. stride is fixed to 1 pixel. Spatial padding is 1 pixel for 3x3 conv. layers. Five max-pooling is adopted in the network, not every conv. layers are followed by max-pooling, the pooling is performed over a 2x2 pixel window, the pooling stride is 2.
Three fully-connected layers is used for classification, the first two have 4096 channels each, the third performs 1000 way ILSVRC classification and thus contains 1000 channels. Final layer is a soft-max layer. Activation function for the whole network is ReLU non-linearity. The whole structure of the network is shown as below:
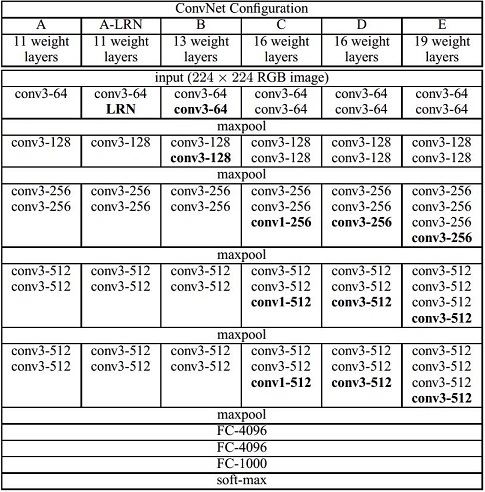
In the above figure, conv3-64 means the receptive field size is 3x3 and the output channel of the conv. op. is 64.
Training
Training batch size is 256, momentum is 0.9, weight decay is 5x10^-4, dropout regularization for the first two fully-connected layers is set to 0.5, SGD learning rate was initially set to 10^-2, and decreased by a factor of 10 when the validation set accuracy stopped improving. The learning rate decreased 3 times in total. In the paper they mentioned about the pre-initialization of certain layers, so the training can converge with less epochs, and they also mentioned about the random initialization, that is initial the weights with zero mean and 10^-2 variance and zero biases.
Comments
From my experience, VGGNet is a structure that is very suitable to verify your idea. It is relatively easy to generalize to different scenario. The drawback of this architecture is that its space complexity is too large. There are many structures that has a smaller size and better performance such as Inceptions.
Inception-v4, Inception-ResNet
Related paper is: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, published on Aug. 2016 by Google.
Achievement
With an ensemble of three residual and one Inception-v4, achieve 3.08% top-5 error on the test set of the 2012 ImageNet classification challenge.
Inception-v4
Inception-v4 is a deeper and wider Inception network. Comparing to Inception-v3, it has more inception modules.
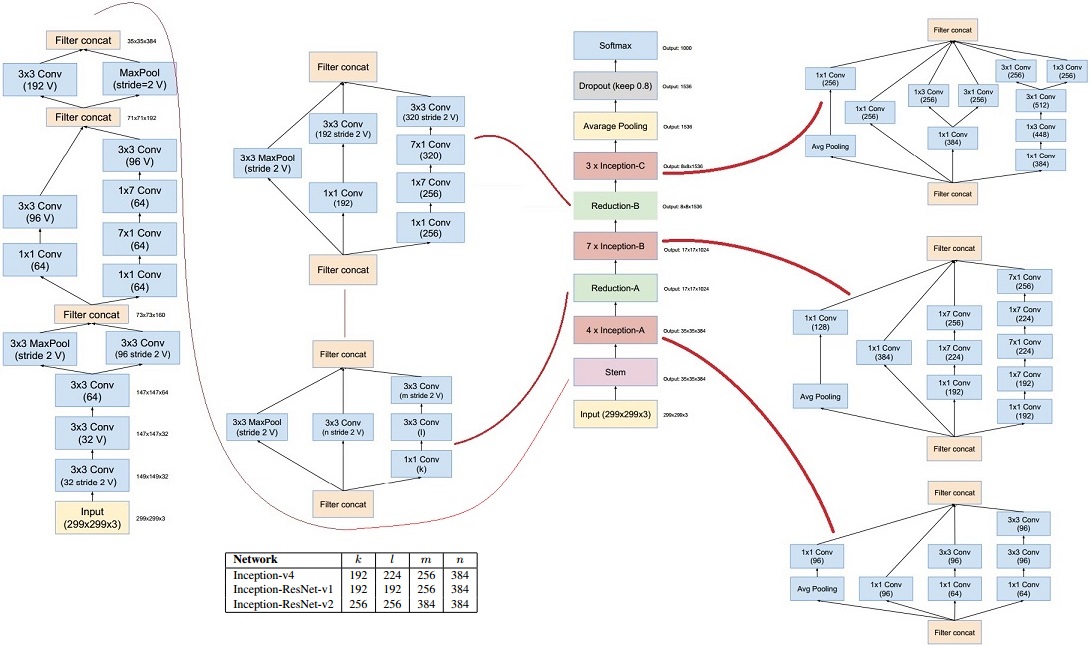
More clear image can be found here.
{kind=link}
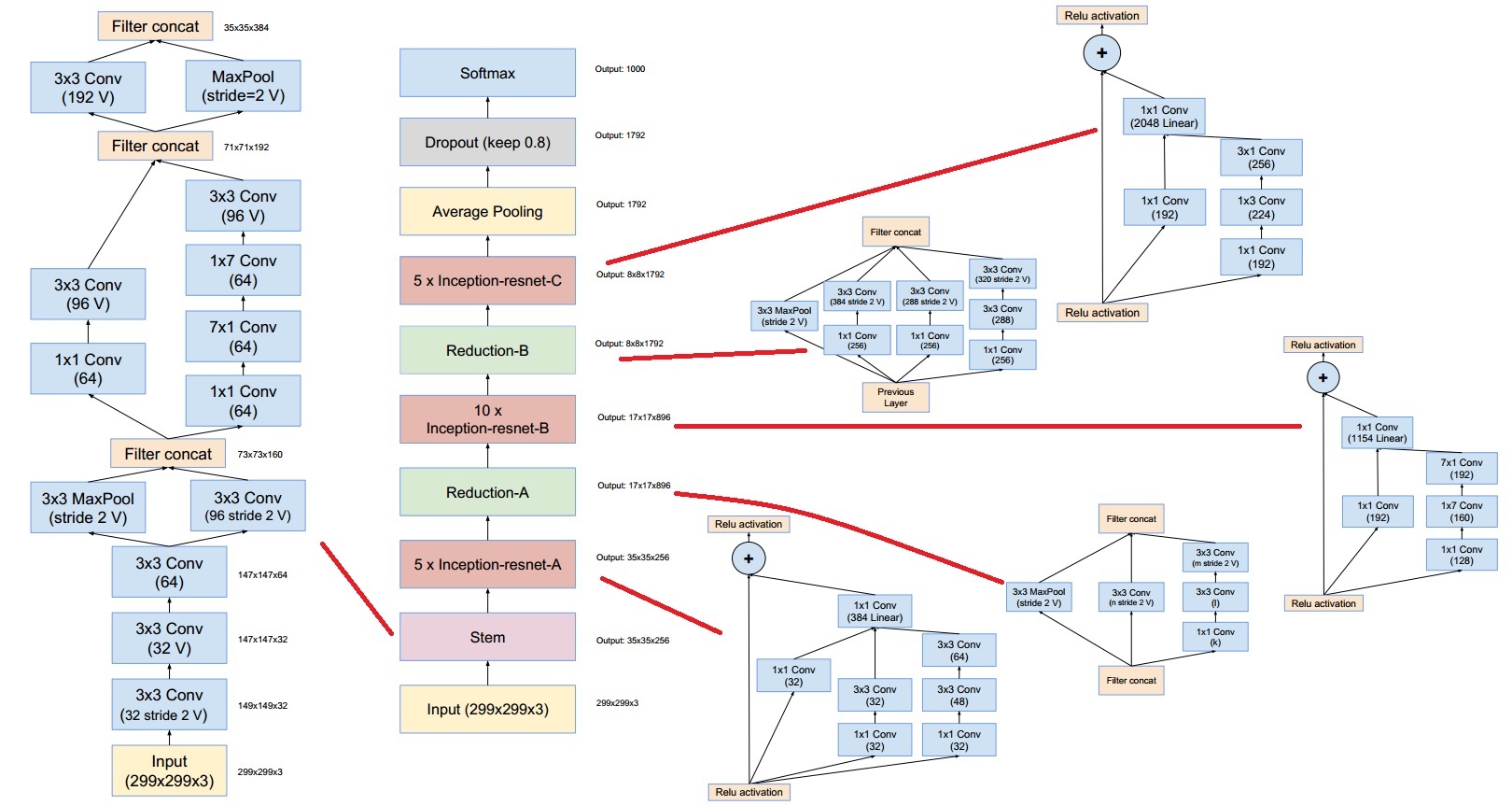
Inception-ResNet
Inception-ResNet is a hybrid of Inception net and Residual net. Currently, Inception-ResNet-2 is the state-of-the-art network structure on ImageNet dataset.
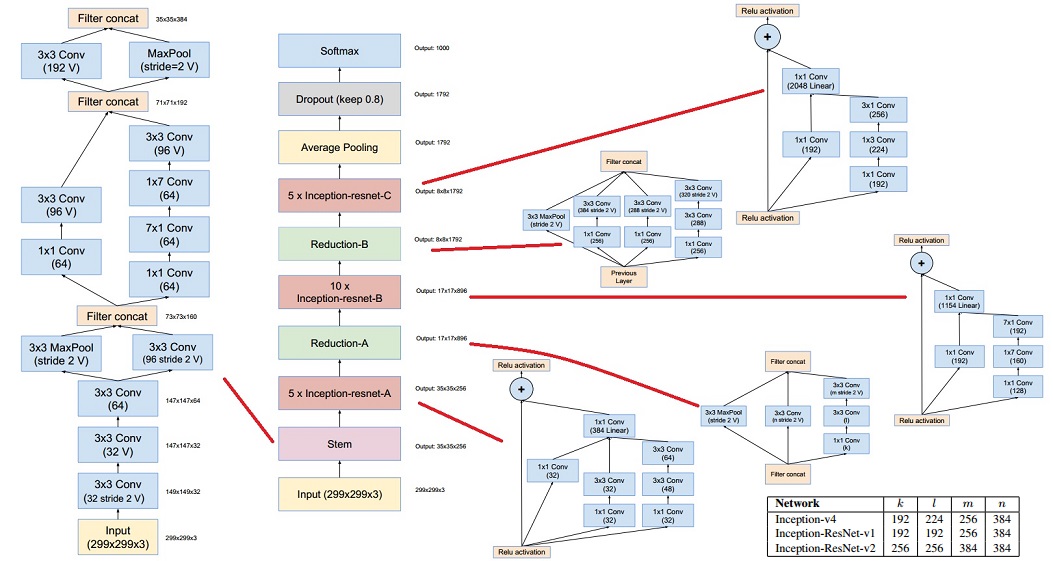
More clear image can be found here
{kind=link}
Conclusions
This paper is more like a report rather than a paper (the authors use report themselves). The general conclusion is that residual connection can speed up the training process but if you do not use residual connection, inception network can also get very good classification result.
License
The content of this blog itself is licensed under the Creative Commons Attribution 4.0 International License.

The containing source code (if applicable) and the source code used to format and display that content is licensed under the Apache License 2.0.
Copyright [2016] [yeephycho]
Licensed under the Apache License, Version 2.0 (the “License”);
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
Apache License 2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an “AS IS” BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either
express or implied. See the License for the specific language
governing permissions and limitations under the License.
