This post is an introduction to neural style program. Neural style is a CNN based algorithm to apply an image’s style to another image, this it the most interesting program which is related to deep learning I ever found. The source code is published on the Github, Torch7 version and tensorflow version.
The related papers are A Neural Algorithm of Artistic Style published on Sep. 2015, Image Style Transfer Using Convolutional Neural Networks published on 2016, and for videos Artistic style transfer for videos, published on Apr. 2016.
Allow me to show you some pictures here:

Source first two images comes from the Internet, click on the The Summer, Poppy Field and the The Starry Night to view the original image.
Recently, I found a website can do the same thing for you, click deepart to get your own styled image! I believe this is a good advertise to amazon cloud service.
An mobile App named Prisma can also do that if you like.
Principle
Here I’m going to describe the math behind the neural style program. I assume that the reader has the basic knowledge on convolutional neural network and VGG net.
Inputs, Outputs and Other Things You Need
To make the algorithm work, you need the following input components:
- A pre-trained VGG network model
- A style image which will be used as the template, your output image will imitate the style of this image. In the example above, Von Gogh’s starry is the style image.
- A content image, the output image will imitate the content in the content image. In the example above, Monet’s The Summer, Poppy Field is the content image.
- A random white noise image (output image). This image will be the prototype of the output image and it will learn from style image and content image by gradient descent algorithm.
And you will get:
- A output image which contains the content of the target image and the style of the style image.
Deal With The VGG Model
As we all know that VGG net is a very influential convolutional neural network architecture aims at image classification, segmentation or image object localization. In this program, you need a pre-trained VGG net on the image classification. Both the Torch version and the Tensorflow version provide the pre-trained model.
This algorithm uses VGG-19 model, it contains 16 conv. (with activations) layers and 5 pooling layers, the difference is that neural style algorithm doesn’t require fully connected layer as classification algorithm, so at the last of the network, fully connected layer can be removed directly, the output of final layer should be feature maps of the conv. net.
Another difference is that they replace maxpooling which is applied in classification with the average pooling, they claim that average pooling gives more appealing outcome.
Content Representation
Feed the content image to the VGG net, at each layer of the network, we can get feature maps, the deeper the network, the more abstract the feature maps are, but generally speaking, we presume that these feature maps contain the content information of the content image, in fact, these feature maps contains the features of the contents of the original image, these features are good enough to represent the content of the original image.
Lets’s say, after the l th conv. layer in VGG net, there are N conv. feature maps, each feature maps has the size of M, M comes from the width times height of a feature map. We use:

In this process, we feed a random noise image to the network, and if we try to minimize the loss between the random image and the content image, the content of the random image will looks more and more like content image. Imagine, if we do not use CNN, how can we make two images alike? I suppose the solution is to compare the pixel values at the same position of two image and adjust the random image pixel values according to the content image pixel values. Here, the difference is that they do not directly compare the pixels of two different images, instead, they compare the high level CNN feature maps of two image, use the gradient descent to adjust the pixel values and at last use the CNN visualization method to reconstruct the random image (after the first iteration the image is no longer random, we will call it output image since now on).
Style Representation
Feed the style image to the network and also we will get many feature maps at different level. But style is an abstract concept even for human, so what really happens here is nothing but math. The foundation of the style representation is based on other related research, so if you are interested, go and check the reference papers listed by this paper, maybe Texture Synthesis Using Convolutional Neural Networks is a good start.
The principle is like the style information of an image is hidden in the feature maps in the same layer of the network, the correlations between different feature maps can somehow represent the style of the image.
Let’s go back to math:

In this process, the output image will try to imitate the correlations between different feature maps of the style image.
Whole Process
The transfer process can be shown as follows:
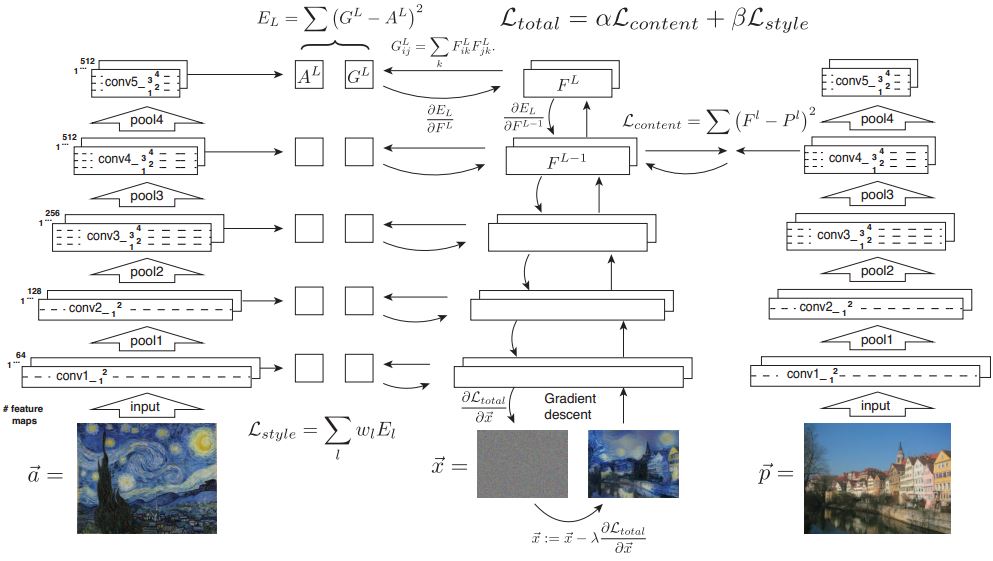
The whole process takes above two sorts of representation into consideration. Use linear combination of content loss and style loss to form up a total loss, and use the gradient descent to minimize the total loss.
Then keep update your output image and feed the new output image again and again. After a few times of iteration, you will be able to get a well tuned image which has the content of the content image and the style of the style image. And you can adjust the combination factor of the total loss, if content loss has a larger factor, the generated image will look more like the content image.
License
The content of this blog itself is licensed under the Creative Commons Attribution 4.0 International License.

The containing source code (if applicable) and the source code used to format and display that content is licensed under the Apache License 2.0.
Copyright [2016] [yeephycho]
Licensed under the Apache License, Version 2.0 (the “License”);
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
Apache License 2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an “AS IS” BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either
express or implied. See the License for the specific language
governing permissions and limitations under the License.
